What DALL-E thinks “Oracle Database Release Notes Documentation Bug” looks like
Update: In Feb 2024 Oracle updated the release notes to fix most of the below! They still have the un-needed export of the CV_ASSUME_DISTID, but they did add the steps about patching with the 19.22 patch during install and updating opatch. Thanks!
In January 2024, Oracle released a new version of the Oracle 19c release notes. They also released the 19.22 patchset for Oracle Database. The great news is that with the 19.22 release, Oracle has finally got the Oracle Database on-premises install on Oracle Linux 9 stuff knocked out. It works ‘out of the box’ now. However, if you look at the release notes and navigate to the section entitled “Known Issues and Bugs for Oracle Linux 9 and Red Hat Enterprise Linux 9“, and then navigate to the 19.22 subsection, you’ll see this:
And, well… It’s not really that simple. If you didn’t have 35 years of experience reading Oracle release notes, you might take that statement at face value. Things won’t go well for you if you did. Instead, you have to peer up at the 19.21 section to see the following steps (but of course you are installing 19.22, not 19.21, so you don’t need to pay attention to that section, right?):
Single-instance Oracle Database (19.21):
Set the environment variable CV_ASSUME_DISTID to OL8 ($export CV_ASSUME_DISTID=OL8).
Unzip the 19.3.0.0.0 Oracle Database gold image.
Copy the OPatch utility version 12.2.0.1.40 or later from My Oracle Support patch 6880880 by selecting the 19.0.0.0.0 release.
That’s quite a bit different than the 19.22 section that says “No additional patches are required for installing Oracle Database 19c Release 19.22 on Oracle Linux 9 or Red Hat Enterprise Linux 9“.
Having just done a lot of testing of this on Oracle Linux 9, here’s what (in my opinion) the release notes should actually say in the Single-instance Oracle Database (19.22) section:
Single-instance Oracle Database (19.22):
Unzip the 19.3.0.0.0 Oracle Database gold image to your ORACLE_HOME location (for example /u01/app/oracle/product/19.0.0.0/dbhome_1).
Download the OPatch utility version 12.2.0.1.40 or later from My Oracle Support patch 6880880 by selecting the 19.0.0.0.0 release. $ cd /u01/app/oracle/product/19.0.0.0/dbhome_1 $ rm -rf OPatch $ unzip -q /usr/local/src/oracle/patch_downloads/p6880880_122010_Linux-x86-64.zip
With 19.22 you don’t need to modify the $ORACLE_HOME/cv/admin/cvu_config file or export the CV_ASSUME_DISTID environment variable to get the install to work correctly.
Even though you can now select the 19.0.0.0.0 “Release” of OPatch, you’ll actually get a version that is 12.X (see image below).
The OJVM patch is optional, but I like to see my opatch lspatches command look very clean (see below).
On Tuesdays Cary Millsap runs a meeting for Method-R customers to chat about Oracle stuff. Often he has something prepared, but this Tuesday he didn’t. Doug Gault decided to share an image that finally helped him get his head around the ANSI SQL syntax. Doug has been around the Oracle world for a long time but he’s always been able to work with Oracle proprietary SQL so he never really learned the ANSI SQL syntax. Recently he got assigned to a project where ANSI SQL is mandated so he had to get everything straight in his head. He shared an image that he had created from some training and we all took a look at it. Me, being me, I immediately jumped in with what I thought would be improvements to the image. I was challenged to come up with a better image, and so, I created the below.
My hope is that this will help some folks move away from the horrible (in my opinion) Oracle propriety SQL syntax to the totally awesome ANSI SQL syntax. I think the Oracle syntax is horrible because where clauses in queries end up doing two things; joining table AND filtering rows. With the ANSI syntax, join clauses join tables and where clauses only filter rows.
A note on the above: I used the preferred USING syntax to join tables for the ANSI queries:
join using (deptno)
instead of the ON syntax to join tables
join on e.deptno = d.deptno
I believe this is easier to read and understand and, in general, less code is better code, and this is smaller. If you use the USING syntax just note that you no longer associate the column with one table or another in the other clauses (like SELECT or WHERE) but instead leave it unconstrained. For example:
select deptno, e.ename, d.dname from emp e join dept d using (deptno) where deptno > 20;
If you were to qualify the DEPTNO column in either the select clause or the where clause (d.deptno for example) you’d get an ORA-25154: column part of USING clause cannot have qualifier message.
I’ve been working on an upgrade of Oracle Database on Windows. Despite working with Oracle Database for over 30 years, I really never spent a whole lot of time working on a Windows server. Unix, Solaris, Linux, heck even AIX, oh yeah. Windows, not so much.
While attempting to patch a brand new software-only install of Oracle 19c from the original 19.3 up to 19.21 I kept on getting UtilSession failed: Prerequisite check “CheckActiveFilesAndExecutables” failed during my opatch apply. It appeared that the JDK home in my ORACLE_HOME was in use. Of course, this didn’t make any sense since there wasn’t anything running out of this home.
Here’s what I was seeing:
Following active files/executables/libs are used by ORACLE_HOME: c:\app\oracle\product\19.0.0.0\dbhome_1
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\bin\java.exe
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\java.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\management.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\msvcr100.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\net.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\nio.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\server\jvm.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\verify.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\zip.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\ext\cldrdata.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\ext\localedata.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\ext\zipfs.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\jsse.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\rt.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\bin\java.exe
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\java.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\management.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\net.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\nio.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\verify.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\zip.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\bin\server\jvm.dll
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\jsse.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\rt.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\ext\cldrdata.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\ext\localedata.jar
c:\app\oracle\product\19.0.0.0\dbhome_1\jdk\jre\lib\ext\zipfs.jar
Why were they in use? Why were they listed twice? What Windows process had a lock on them? I couldn’t figure it out.
Time for drastic measures. I downloaded IObit’s Unlocker program (use at your own risk) and used it to look at the files. It was showing no locks on any of those files, but I went ahead and unlocked them anyway. Of course this was it. This had to fix it… Nope! Still broken.
In desperation, I reached out to Oracle Support. And that’s when it finally happened for me. Support generated this:
My Oracle Support has performed a Knowledge search using your Service Request details (Summary, Error codes, Product) and located the following documents which may be related to your issue.
Search Results
====================================================================================
99% - Doc ID 2507120.1 Opatch 11.2.0.3.20 : Applying PSU/Windows BP fails with:'To run in silent mode, OPatch requires a response file for Oracle Configuration Manager (OCM)', 'error code = 73'
99% - Doc ID 1475147.1 OPatch - Failed to load the patch object. Possible causes are: OPatch failed with error code = 73 LsInventorySession failed:
99% - Doc ID 2950970.1 opatch apply fails with Error:" Prerequisite check "CheckActiveFilesAndExecutables" failed" on $oracle_home/jdk files
99% - Doc ID 1472242.1 Applying Patch Fails as Copy Failed for crsctl.bin as EM dbconsole was not Stopped
99% - Doc ID 2978449.1 "opatch util verify" reports OUI-67073:UtilSession failed: Files are not updated completely & OUI-67124:Files check failed: Some files under oracle_home are not patched , after applying RU Patches
Wait… That third Doc ID looks exactly like my error. I took a look and started reading and while it didn’t match my situation, it did mention the problem. Someone had downloaded opatch for the wrong platform. Could I really have done that? You betcha! (been watching a lot of Fargo with my wife, and “Minnesotan” is very catchy).
I got a new version of OPatch, this time for Windows instead of for Linux and you know what? Everything worked just fine.
In over 30 years of using Oracle Support, this is the first time I’ve ever had the “Oracle Support did a search and we found these documents” actually have the solution to my problem!
It appears that the physical contents of the cwallet.sso and ewallet.p12 files changed enough between Oracle 11 and Oracle 19 that the Oracle 19.15 (19.21 was also tested) binaries no longer liked the physical contents of the TDE wallet files even though the logical contents were correct. Overwriting the existing contents of the old “Oracle 11 style” wallet files with the Oracle 19 binaries with the exact same logical contents allowed the database to work as expected. This happened somewhere between Oracle 19.8 (old Oracle 11 style wallet works fine) and Oracle 19.15.
The Problem
Recently we had an interesting situation where a database that had been upgraded over the years, from Oracle 10 to eventually Oracle 19.8, wouldn’t upgrade to 19.15 cleanly. Once the ORACLE_HOME binaries had been updated to 19.15 (datapatch had yet to be applied) the database would only open in restricted mode and the following message would appear in the alert logs:
ALTER DATABASE OPEN detects that an encrypted tablespace has been restored but the database key has not been activated, or the database has been flashback'ed prior to first set key of the master key (pdb 0). Database is open in RESTRICTED MODE only. Please select the latest master key from V$ENCRYPTION_KEYS and execute ADMINISTER KEY MANAGEMENT USE KEY command, and restart the database
We could force the database to open in read write, and then run datapatch and everything would appear to work correctly, but this seemed kind of buggy because any bounce of the instance would still cause the database to open in restricted mode with the same error message in the alert log and we’d have to repeat the force to read write mode again.
This behavior was very strange because there was only a single TDE (Transparent Data Encryption) key in the wallet and it was obviously working just fine with the Oracle 19.8 binaries. However, if you looked into the data dictionary, you’d notice that the creation date and activation date in the old wallet were both NULL and there was also a NO value for masterkey_activated in the data dictionary even though the master key was very obviously activated since we could read and write to encrypted tablespaces just fine.
Some Details
The database name is going to be orcl, and it will be a standalone database, not a pluggable database in a container database.
The database was created a long time ago as an Oracle 10 database, upgraded to Oracle 11 at which point the transparent data encryption wallet was added and an encrypted tablespace was created using Oracle 11.1 binaries (which was when TDE for tablespaces was first introduced).
The database has an encrypted tablespace with a bunch of tables in it.
The database has a TDE wallet (located here: /u01/app/oracle/admin/orcl/tde_wallet) with the two important files: ewallet.p12 which, of course, contains the actual TDE key and is secured with a password (oracle_4U which, of course, is a bad TDE wallet password because you want your TDE keys file to be pretty secure), and the cwallet.sso file which contains an encrypted version of the oracle_4U password needed to read the ewallet.p12 file). The important detail for these two files is that they were created with Oracle 11.1 binaries which appears to have less information in them than if they were created with the Oracle 19 binaries.
The database is open and the wallet is open with a wallet_type of AUTOLOGIN.
All SQL commands were entered using a bequeath connection on the database server (sqlplus / as sysdba).
Almost certainly this bug exists because the v$encryption_keys view has a NULL for activation_time and the v$database_key_info view has NO as the value for masterkey_activated. These values appear to be read directly from the ewallet.p12 file and it appears that the Oracle 11.1 binaries never set those values in the ewallet.p12 file.
The Fix
For some operations with a TDE wallet, it appears you need to have a password based wallet type and not an auto_login based wallet type. Since our database is currently open with an auto login wallet, we’ll close the wallet and re-open it as a password based wallet. You may not need to move the old cwallet.sso file, but we moved the cwallet.sso file to old.cwallet.sso before we did the below command. The DBA had backed out the 19.15 binaries, so all of the below commands were done with the 19.8 binaries.
SQL> administer key management set keystore close;
We didn’t need to supply a password when closing the wallet because it is currently an autologin wallet.
Next, we’ll open the wallet using a password.
SQL> administer key management set keystore open identified by oracle_4U;
A query against v$encryption_wallet will now show a status of OPEN and a wallet_type of PASSWORD. We can now modify the wallet to contain the exact same logical contents that it currently contains. We’ll first find the key that is currently in use. In our case there was only a single key since the key had never been rotated. If you’ve rotated keys in the past, make sure to choose the currently activated key which is the one in v$encryption_keys with the highest creation_time or activation_time. Interestingly with the old 11.1 wallet, both these values were NULL, which is almost certainly why this bug exists in the first place (apparently, even Oracle can make mistakes with NULLs!).
SQL> select key_id, creation_time, activation_time from v$encryption_keys;
Now, using the key from above, we’re going to ‘update’ the wallet to use the exact same key that it’s already using. Note that you’ll enclose the key in ticks since it’s a literal value.
SQL> administer key management use key 'TheKey_IDValueFromTheQueryAbove' identified by oracle_4U with backup;
The ‘with backup’ clause automatically saves the previous version of the ewallet.p12 file and renamed it to include the current date and time. It was at this point that we noticed that the new ewallet.p12 file which contained the exact same key as the older ewallet.p12 file had grown in size. On our system, we went from an old file size of 1573 bytes to new file size of 2987 bytes.
Additionally, a query against v$encryption_keys showed that our previously NULL activation_time was now set to the time the previous command was run. And v$database_key_info now had the correct value of YES for masterkey_activated.
Our next step was to recreate the cwallet.sso file using the newly created ewallet.p12 file.
SQL> administer key management create auto_login keystore from keystore '/u01/app/oracle/admin/orcl/tde_wallet' identified by oracle_4U;
If you check the file size of the new cwallet.sso file (remember, we had moved our old one before so we could open the wallet with a password) against the old file you should notice that the new file is larger than the old one even though, again, it contains the exact same logical contents as the previous file (the encrypted oracle_4U password). On our system the old cwallet.sso file was 1883 bytes and the new cwallet.sso file was 3032 bytes.
Now a query against v$encryption_wallet still shows us that the wallet type is PASSWORD. Interestingly we can change this to AUTOLOGIN while keeping the wallet open with the following command.
SQL> administer key management set keystore close identifed by oracle_4U;
One would sort of expect this to actually close the wallet, but instead, it doesn’t close the wallet, it just updates the wallet_type column of v$encryption_wallet from PASSWORD to AUTOLOGIN.
At this point, one of the DBAs noticed that the fully_backed_up column in v$encryption_wallet was still NO. This is because although we had backed up our previous wallet key file, we had yet to back up the current version of the wallet key file (remember, this is the ewallet.p12 file). Just for fun (or was it just to be pedantic?) we did that next.
SQL> administer key management backup keystore force keystore identified by oracle_4U;
While logically our wallet file contents hadn’t really changed at all (one key in the ewallet.p12 and one password in the cwallet.sso), the updated wallet files created with the 19.8 binaries allowed our upgrade from 19.8 to 19.15 to go exactly as expected and we didn’t get a repeat of the database opening in restricted mode, almost certainly because the activation_time in the ewallet.p12 file for the key was no longer NULL.
I’ve mentioned this presentation before on my blog and now I’ve recorded the entire thing including the bonus content. At the various user groups like RMOUG and Kscope, I was only given an hour and just told folks to “Read the rest of the presentation.” The media team at Insum (thanks Marc and Lauren!) and I bounced back and forth on doing multiple 1-hour events or jamming everything into a single presentation. Eventually, we decided to get it done in one go. It’s long… 2 hours and 6 minutes long. Apparently, I was enjoying myself so much that I didn’t even realize that, and if you do watch until the end you’ll notice that I thought it was actually 1 hour long, not 2.
I’m pretty pleased with the presentation and I’ve got a lot of good feedback from folks. If you want to use APEX and/or ORDS and your DBAs and/or System Admins don’t want to implement it, this presentation is my gift to you. Any DBA or System Admin should be able to learn exactly what they need to know to run APEX and ORDS in a production-ready configuration.
The first thing that bothered me was the ‘possible missing index’ result. I did some testing, and I couldn’t come up with a situation where I’d get a missing index result, but the index really was there, so I made the results just say “Missing” if I couldn’t find the index.
Lance and I also cleaned up a few column names to make things easier to understand. For example, I previously had a column named foreign_key_index that had either “Exists” or “Missing” which really wasn’t a foreign_key_index, but instead a flag showing the status of the foreign key index. This was renamed to “index_existence”. Other columns got better names too.
Lance made a suggestion to take the final query and make it a CTE (Common Table Expression, sometimes called a “with clause”), and then create a new simple final query that just selected each column name from the CTE making it very easy for folks to comment out columns if they are not interested in them, or to re-order the columns if they wanted.
We also added another column to the report with the DDL that would create an index that would eliminate the missing foreign key index.
Some notes on that DDL statement:
I’m a very big fan of naming things what they are so my index name ends up being quite long. You’ll almost certainly need to have long object names enabled in your database if you want to use the index name as is. If you need a shorter name, you can just modify the query.
If the query returns multiple foreign key indexes to create on a single table, take a look and see if one of the multicolumn indexes would also eliminate the need for some of the indexes that have fewer columns. Remember though, that the columns need to be in the right order. So if your table has a foreign key constraint on columns c1, c2, c3, and c4 that points to one table and then another foreign key constraint just on only c4 that points to another table, an index on c1, c2, c3, and c4 in that order will be able to be used for foreign key constraint number one, but not for foreign key constraint number two.
I always use lowercase to write all my statements as science says that this is easier for humans to read. All lowercase letters are also much easier to write. When my statements are run, the data dictionary is always populated in uppercase because I never double-quote any of the schema, table, or column names. Some people (and this is never recommended) actually double-quote table and column names and put names in lowercase or mixed-case in the data dictionary which means that every statement that accesses those objects must reference those objects as double-quoted identifiers. Amazingly you can also create schemas in lowercase too! I would never, never do this as you’re just making all your code harder to read and write. I debated on allowing for this craziness, but in the end decided that, yeah, it’s probably better to just help the misguided folks who do this so the owner, table name, and column name(s) in the DDL statement are all double-quoted identifiers as they are stored in the data dictionary. The DDL isn’t as pretty, but it works for more people.
The query could also be just a bit more efficient by eliminating the first column, index_existence. The DDL column now is effectively the same information. I left it because I think it adds some value and would make filtering a bit easier to read.
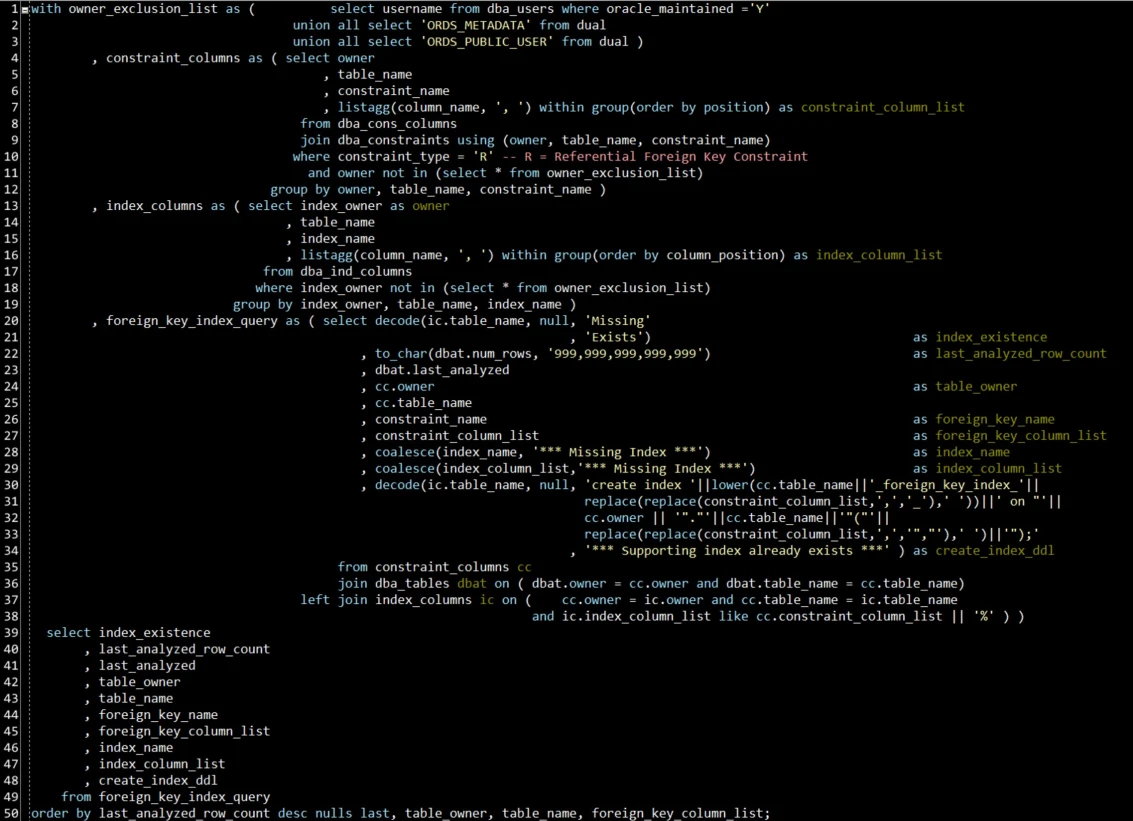
I’ve formatted the query below to be easy to read when displayed with at least 144 columns of width (see the image above). Below the code doesn’t look as pretty because there are not 144 columns of width in the text block.
To that end, here’s the “better” query:
with owner_exclusion_list as ( select username from dba_users where oracle_maintained ='Y'
union all select 'ORDS_METADATA' from dual
union all select 'ORDS_PUBLIC_USER' from dual )
, constraint_columns as ( select owner
, table_name
, constraint_name
, listagg(column_name, ', ') within group(order by position) as constraint_column_list
from dba_cons_columns
join dba_constraints using (owner, table_name, constraint_name)
where constraint_type = 'R' -- R = Referential Foreign Key Constraint
and owner not in (select * from owner_exclusion_list)
group by owner, table_name, constraint_name )
, index_columns as ( select index_owner as owner
, table_name
, index_name
, listagg(column_name, ', ') within group(order by column_position) as index_column_list
from dba_ind_columns
where index_owner not in (select * from owner_exclusion_list)
group by index_owner, table_name, index_name )
, foreign_key_index_query as ( select decode(ic.table_name, null, 'Missing'
, 'Exists') as index_existence
, to_char(dbat.num_rows, '999,999,999,999,999') as last_analyzed_row_count
, dbat.last_analyzed
, cc.owner as table_owner
, cc.table_name
, constraint_name as foreign_key_name
, constraint_column_list as foreign_key_column_list
, coalesce(index_name, '*** Missing Index ***') as index_name
, coalesce(index_column_list,'*** Missing Index ***') as index_column_list
, decode(ic.table_name, null, 'create index '||lower(cc.table_name||'_foreign_key_index_'||
replace(replace(constraint_column_list,',','_'),' '))||' on "'||
cc.owner || '"."'||cc.table_name||'"("'||
replace(replace(constraint_column_list,',','","'),' ')||'");'
, '*** Supporting index already exists ***' ) as create_index_ddl
from constraint_columns cc
join dba_tables dbat on ( dbat.owner = cc.owner and dbat.table_name = cc.table_name)
left join index_columns ic on ( cc.owner = ic.owner and cc.table_name = ic.table_name
and ic.index_column_list like cc.constraint_column_list || '%' ) )
select index_existence
, last_analyzed_row_count
, last_analyzed
, table_owner
, table_name
, foreign_key_name
, foreign_key_column_list
, index_name
, index_column_list
, create_index_ddl
from foreign_key_index_query
order by last_analyzed_row_count desc nulls last, table_owner, table_name, foreign_key_column_list;
2024-02 Update: As my friend Anton Nielsen pointed out, not everybody has DBA privs… If you don’t, just do a search and replace of “dba_” with “all_”. Then you can run this as a non-privileged user and you’ll be sure to capture missing indexes in your own schema and any other schema you can see.
2024-03 Update: Jeff Smith gave the Insum team an overview of the SQL Developer extension for VSCode. His blog post shows how to add snippets to VSCode SQL Developer. I thought I’d give it a shot and created the following which works like a charm. Using “ffk”, for “Find Foreign Keys” will give you the above query if you put the following into your oracle_sql.json file.
"ffk": { "prefix": "ffk", "body": [ "with owner_exclusion_list as ( select username from dba_users where oracle_maintained ='Y'", " union all select 'ORDS_METADATA' from dual", " union all select 'ORDS_PUBLIC_USER' from dual )", " , constraint_columns as ( select owner", " , table_name", " , constraint_name", " , listagg(column_name, ', ') within group(order by position) as constraint_column_list", " from dba_cons_columns ", " join dba_constraints using (owner, table_name, constraint_name)", " where constraint_type = 'R' -- R = Referential Foreign Key Constraint", " and owner not in (select * from owner_exclusion_list)", " group by owner, table_name, constraint_name )", " , index_columns as ( select index_owner as owner", " , table_name", " , index_name", " , listagg(column_name, ', ') within group(order by column_position) as index_column_list", " from dba_ind_columns ", " where index_owner not in (select * from owner_exclusion_list)", " group by index_owner, table_name, index_name )", " , foreign_key_index_query as ( select decode(ic.table_name, null, 'Missing'", " , 'Exists') as index_existence", " , to_char(dbat.num_rows, '999,999,999,999,999') as last_analyzed_row_count", " , dbat.last_analyzed", " , cc.owner as table_owner", " , cc.table_name", " , constraint_name as foreign_key_name", " , constraint_column_list as foreign_key_column_list", " , coalesce(index_name, '*** Missing Index ***') as index_name", " , coalesce(index_column_list,'*** Missing Index ***') as index_column_list", " , decode(ic.table_name, null, 'create index '||lower(cc.table_name||'_foreign_key_index_'||", " replace(replace(constraint_column_list,',','_'),' '))||' on \"'|| ", " cc.owner || '\".\"'||cc.table_name||'\"(\"'||", " replace(replace(constraint_column_list,',','\",\"'),' ')||'\");'", " , '*** Supporting index already exists ***' ) as create_index_ddl", " from constraint_columns cc", " join dba_tables dbat on ( dbat.owner = cc.owner and dbat.table_name = cc.table_name)", " left join index_columns ic on ( cc.owner = ic.owner and cc.table_name = ic.table_name ", " and ic.index_column_list like cc.constraint_column_list || '%' ) )", " select index_existence", " , last_analyzed_row_count", " , last_analyzed", " , table_owner", " , table_name", " , foreign_key_name", " , foreign_key_column_list", " , index_name", " , index_column_list", " , create_index_ddl", " from foreign_key_index_query", "order by last_analyzed_row_count desc nulls last, table_owner, table_name, foreign_key_column_list;" ], "description": "Find unindexed foreign keys" }
I’ve always been a bit unhappy with most (all?) of the queries you find when searching for “Oracle unindexed foreign keys query” on Google. Certainly, the ones that don’t use listagg to aggregate the constraint columns and the index columns are insane. I realize those queries might have been around since before listagg was available, but listagg was introduced in 11gR2 which was released in 2009.
To that end, the following 33 line query will find all the possibly unindexed foreign key constraints in your database. Since the matching happens on the column names, if you have a difference in column names between the constraint columns and the index columns, you won’t get a match and it will show up in the results as ‘Could be missing’. 99.99 times out of a hundred the index is missing.
I’ve also added the number of rows and last analyzed date from DBA_TABLES (remember, this number of rows may not be accurate as the value is only updated when the table is analyzed) so that the biggest possible offenders would be the first results. Even if the number of rows is small and the statistics are up to date, you’ll pretty much always want to have that foreign key index to eliminate over-locking the detail rows when a master row is updated. In all my years I’ve yet to run across a business application where the ‘index caused too much overhead’ and needed to be removed. I’m not saying those situations don’t exist, but they are exceedingly rare.
If you want to see how Oracle is doing with its schemas, you could change the owner_exclusion_list CTE (Common Table Expression, sometimes called a WITH clause) to something like “select ‘nobody’ from dual’). Right now that CTE gets the list of schemas that are Oracle maintained and adds in the ORDS_METADA and ORDS_PUBLIC_USER schemas which are, for some reason, not marked as Oracle maintained.
Using an APEX page to display the results of the query also allows me to format the last analyzed date using APEX’s “since” formatting, which gives a really good indication of possible stale statistics.
with owner_exclusion_list as ( select username from dba_users where oracle_maintained ='Y'
union all select 'ORDS_METADATA' from dual
union all select 'ORDS_PUBLIC_USER' from dual )
, constraint_columns as ( select owner
, table_name
, constraint_name
, listagg(column_name, ', ') within group(order by position) as constraint_column_list
from dba_cons_columns
join dba_constraints using (owner, table_name, constraint_name)
where constraint_type = 'R' -- R = Referential Foreign Key Constraint
and owner not in (select * from owner_exclusion_list)
group by owner, table_name, constraint_name )
, index_columns as ( select index_owner as owner
, table_name
, index_name
, listagg(column_name, ', ') within group(order by column_position) as index_column_list
from dba_ind_columns
where index_owner not in (select * from owner_exclusion_list)
group by index_owner, table_name, index_name )
select decode(ic.table_name, null, 'Could be missing'
, 'Exists' ) as foreign_key_index
, to_char(dbat.num_rows, '999,999,999,999,999,999') as last_analyzed_row_count
, dbat.last_analyzed
, cc.owner
, cc.table_name
, constraint_name as foreign_key_constraint_name
, constraint_column_list as foreign_key_column_list
, coalesce(index_name, '*** Possible Missing Index ***') as index_name
, coalesce(index_column_list,'*** Possible Missing Index ***') as index_column_list
from constraint_columns cc
join dba_tables dbat on ( dbat.owner = cc.owner and dbat.table_name = cc.table_name)
left join index_columns ic on ( cc.owner = ic.owner and cc.table_name = ic.table_name
and ic.index_column_list like cc.constraint_column_list || '%' )
order by dbat.num_rows desc nulls last, cc.owner, cc.table_name, constraint_column_list;
Let me know if this query is helpful, and happy DBAing/Developing!
Note: On my Twitter post about this blog, I took a screenshot and put in the alt text for the image with the username column in the first CTE as ‘username’ instead of just username. This means that the Oracle maintained schemas are NOT excluded anymore. I was testing on a database that only had a single schema and wanted to include the Oracle schemas too. I also left off the owner column for the list in the final query.
2024-02 Update: As my friend Anton Nielsen pointed out, not everybody has DBA privs… If you don’t, just do a search and replace of “dba_” with “all_”. Then you can run this as a non-privileged user and you’ll be sure to capture missing indexes in your own schema and any other schema you can see.
I’ve been back for a while but thought I’d post some plans for my Kscope content and talk about the conference itself now that it’s in the bag.
I arrived late Friday night and things were pretty quiet. I spent some time in the bar trying various bourbons and whiskeys before calling it an early night.
The next morning I ran into Connor McDonald (check out his amazing content on Youtube). He mentioned that he was planning to go visit the famous Tom Kyte (the original creator of Ask TOM, and author of one of the very best Oracle books, Expert Oracle Database Architecture) but apparently Tom fell off a ladder and broke some ribs. Hopefully, Tom will recover soon. A bit later I joined the team going to the community service day event. They gave us matching shirts to wear and we boarded buses to Mile High Behavioral Healthcare and did a bunch of cleaning, gardening, and painting. I was on the painting crew and painted a gazebo and a few tables with a great team of folks. I ended up buying MHBH some picnic tables after we went to pick up one of their existing picnic tables and it essentially disintegrated. When one of the guests of MHBH asked me “How do I get one of those shirts?” I gave him mine. While the shirt was cool I’m sure he’ll get more use out of it than I would have.
By Sunday the rest of the Insum team had started to show up and we had a great time re-connecting.
Both of my main presentations were on Monday. Thankfully I’d delivered both before, so I was really comfortable with the content although it was going to be my first time delivering my “You know you might have a bad data model when…” presentation in just thirty minutes (I’d been given one of the 30 minute sessions for this presentation). It’s a bunch of slides with the type of queries that you would either see in your applications or queries you can run against your application schemas to see if there might be opportunities for enhancements. Upon the advice of Steven Feuerstein, another member of the Insum team, instead of starting with the theory of normalization, I started with the actual queries. Since the theory portion would take about 5 minutes, my plan was to cut it off at 25 minutes and jump to the theory. I set an alarm on my phone for 25 minutes, let the audience know what I planned to do, and dove in. When I finished my queries section, I glanced at my watch to see how much time I had left. As I was glancing at my watch, the alarm on my phone went off! It was perfect and I got a bit of applause from the audience. I finished off the theory portion and then got a lot of good feedback including from some of the very experienced folks in the audience (Oracle ACE directors, etc.).
Later in the day, I did my “APEX and ORDS for DBAs and System Admins” presentation. While I’ve delivered the content at other events before, I always update my presentations to the latest and greatest software, and with the very frequent updates of both ORDS and APEX I had to update everything a few days before the conference.
This presentation is actually about 2 to 4 hours of content, but I only had an hour to deliver it. Basically, I cut the presentation in half and gave folks a preview of what would be in the 2nd half if I had more time. I also went through the first half of the presentation pretty quickly. The premise of the presentation is that people often come to Kscope and they see all these really cool APEX solutions, but then when they go back to their own IT department the DBA or System Admin just says “No.” The reason for the “No” can be anything they feel like coming up with at the time (“Security”, “Too complicated”, “I don’t know how to do it”, etc.) but the conference attendee doesn’t get the very cool APEX and/or ORDS features that they saw at the conference. To solve this problem, I broke the first half of the presentation into three sections.
Install the APEX database component and patch it in the database. This section shows that APEX is just a component of the database (it shows up in the dba_registry view) and, by showing what is happening in the database we see that there are NO security changes in the database when you do this. It also showed how the installation and patch take under 10 minutes. On my boxes, the APEX install takes usually takes under six minutes and the patch takes under 30 seconds.
Now that you have the APEX component in the database, you have access to bunches of very cool APIs. Some of those APIs enable you to reach out of the database to access things on remote servers if the DBAs allow it. I show exactly how to enable this and how to create and manage an Oracle TLS wallet (yes, people and Oracle often refer to this as an SSL wallet, but we really stopped using SSL back in the 1990s. It’s been TLS for over 20 years… and it really is a TLS wallet). Wallet management can be very tricky and I can’t tell you the number of times I’ve seen very bad wallet setups on Oracle servers. I explain the various wallet types (TDE wallet, SEPS wallet, XDB wallet, and TLS wallet) and show how I build and maintain them.
Finally, we get to the last step which is setting up and configuring ORDS for a production-ready deployment. While Kris Rice, the Oracle lead for the ORDS team, disagrees with me, I really don’t like deploying ORDS with /ords/ in the URL. As Sir Tim Berner’s Lee explains, cool URLs don’t have the technology used to deploy them in the URL. Yes, that link is from 1998. I figure when Kris is knighted by the King he can tell me I’m wrong. I also show how to maintain ORDS over time. I show how to create the best
At this point, I’ve covered the first half of the presentation but an hour has passed and I have to just show folks what the next three sections are:
Adding a database resource manager plan that ‘just works’ for APEX deployments.
Building a Systemd service to run ORDS.
Deploying the ORDS service as a ‘regular’ operating system user instead of the root user. The root user can, of course, deploy ORDS on port 443 (the default HTTPS port) trivially, but some folks would prefer not to run ORDS as root, so I show how to do this.
My plan is to take all of that content and publish it here (update: The entire 2-hour APEX & ORDS for DBAs and System Admins is now live!), but it will take a while. Life is very busy and I’m not exactly sure when I’ll be able to finish it all. Until then, all of the code and examples from my both presentations can be found in the following Github repos:
Finally, I was a co-presenter with Cary Milsap of Method R in a presentation on tracing APEX. It was also well-received and sparked a lot of interesting discussions.
The annual Ride Drive Give event at Circuit of the Americas on Friday May 5th at CotA was a great success. I gave 12 different rides at $500 each to raise $6000 for the charity. Each year the event is a big success.
I was a “Hot Lap Driver” giving people rides in my Revolution.
I even made the Ride Drive Give website as the example for “Racecar Hot Laps”.
The day started with some time blocked out on the schedule for me to rest, but I let the organizers fill up the whole day with rides so I could generate as much as possible for the event.
Of the 12 different riders, only one rider got a bit queasy, so I slowed down a bit for him. For everyone else, it was a ‘pretty brisk’ lap.
It was quite a bit of fun for me too, although I was quite exhausted by the end of the day. I also had both the Boxster race car and the Revolution in my trailer (with, of course, the Revolution in front of the Boxster in the trailer), so I had to load two cars at the end of the day. Danny (one of the other instructors) gave me a hand loading the cars which took much less time than if I did it all myself.
I feel very lucky to be able to give back to the community in this way.
Congratulations! You have been accepted to speak at ODTUG Kscope23, June 25–29, 2023, in Aurora, Colorado!
The following abstract has been accepted for a 60-minute session:
APEX & ORDS for DBAs and System Admins
Followed by:
The following abstract has been accepted for a 30-minute session.
You know you might have a bad data model when…
That was followed up by another email from Cary Millsap of Method-R. Cary submitted a session with me as the co-presenter.
The following abstract has been accepted for a 60-minute session.
Tracing APEX: the Ultimate in Performance Observability
I have the first presentation already done since I just delivered it at the RMOUG conference a few weeks ago. Oracle, of course, released new versions of APEX and ORDS after I thought I was done, including an APEX patch the Monday before I left. I had to scramble to update my content to reflect the new versions right before I left.
Between now and June, Oracle is going to release new versions of APEX and ORDS so I’ll have to update my content for the first presentation.
The 2nd presentation is currently on my whiteboard (It’s really glass… so is it a glass board?) in my office, so I’ll put that together pretty soon.
Cary recently wrote a book that has some good details on his topic for the conference. I’ve been able to review the book and make it a bit better. I’m really looking forward to working with Cary to come up with some compelling content for the conference.
If you are going, you can use code VINS23 to get $100 off your registration. Hopefully, we’ll see you all there!